BUUCTF [GYCTF2020]Ezsqli
[GYCTF2020]Ezsqli
参考:
[GYCTF2020]Ezsqli_[gyctf2020]ezsqli 1-CSDN博客
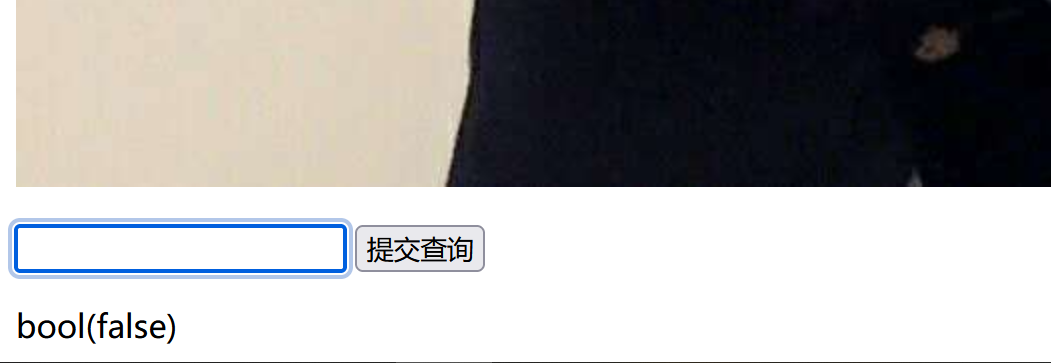

注入点为POST请求获取的id参数
测试注入点之后,发现不返回报错信息,所以只能采用盲注的方式
测试盲注payload:
payload1:
1 | |
payload2:
1 | |
产生两种不同的回显结果,所以可以采用普通盲注
构造普通盲注payload:
payload1:
1 | |
测试payload1是否可行:
payload2:
1 | |
返回两种不同的结果,所以我们的payload可行
爆数据库名:
1 | |
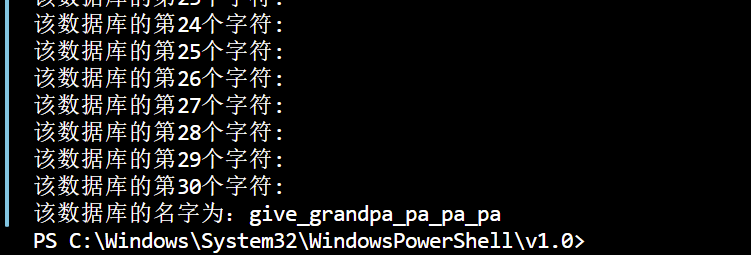
爆出数据库名为give_grandpa_pa_pa_pa
爆数据库的表名:
在使用脚本时发现出错,通过测试payload发现存在对sql语句的过滤:
所以要先测试网页对sql语句有哪些过滤:
1 | |
输出:
1 | |
测试我们的sql语句有哪些黑名单字符:
1 | |
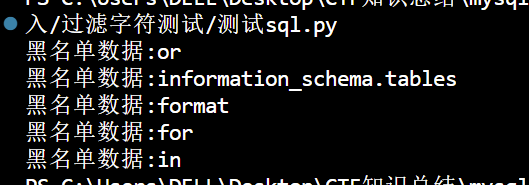
由于我们的黑名单数据中存在对大小写的过滤,所以需要考虑其他的绕过方式,又因为这里的黑名单数据都是只存在于information_schema.tables中,所以我们只需要将其替代就可以绕过
InnoDb引擎(information_schema.tables的代替):
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
sys数据库:
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns来获取表名。
构造新的payload获取表名:
1 | |
测试payload:

成功绕过!!!
爆表名脚本:
1 | |
输出:

数据表名:users233333333333333,f1ag_1s_h3r3_hhhhh
无列名注入法:
由于网页过滤了information_schema,同时sys.schema_table_statistics_with_buffer不存储列名,所以我们无法获取数据库的列名,所以只能采用无列名的方式进行注入:
本地数据库测试:
flag数据表:
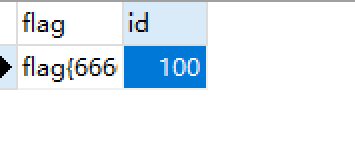
sql语句:
1 | |
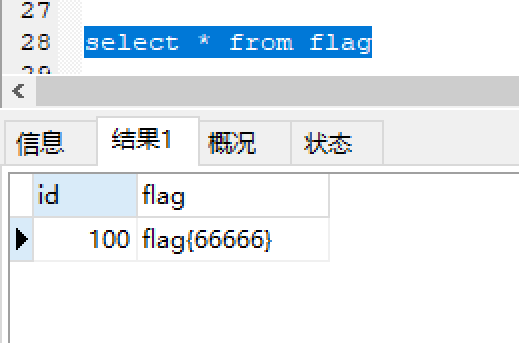
mysql的元组比较法:
1 | |
报错情况:
1 | |
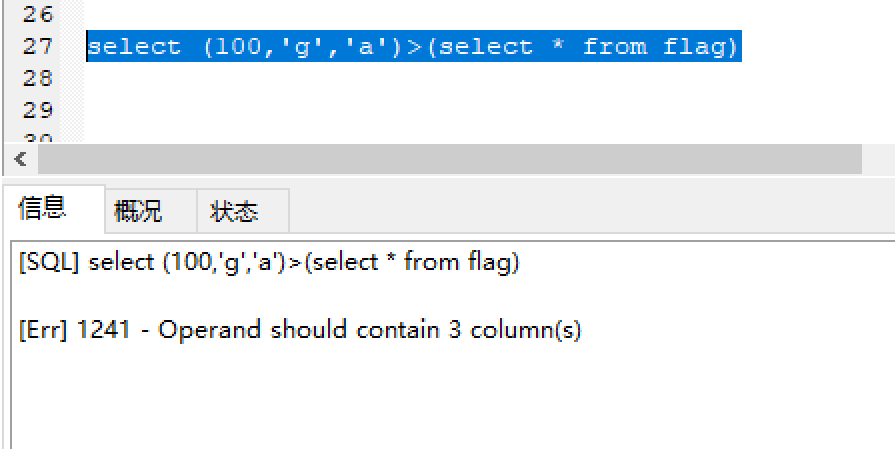
它会要求>后面的操作语句至少查询出三个字段
比较方式:
1 | |
了解了mysql的元组比较法,我们知道我们需要清楚表的字段个数,使用payload进行测试
构造payload获取表字段数:
payload1:
1 | |

返回错误,即没有返回0或1的两种响应信息,说明sql语句发生报错,所以字段数不是1
payload2:
1 | |

返回0时的页面信息,所以可以证明f1ag_1s_h3r3_hhhhh表的字段数为2,接下来就要确定f1ag_1s_h3r3_hhhhh表的第一个字段的值为多少
构造payload证明f1ag_1s_h3r3_hhhhh表第一个字段不是以flag{开头:
1 | |
因为flag都已flag{xxxxx}的形式存在,所以如果第一个字段为flag{xxxx},则该payload应该返回1^0:
返回的是1^0的情况,所以可以说明第一个字段不是flag所在字段,这里如果返回的是1^1的情况时,可能还需要考虑更多的情况,因为如果第一个字段的值确实比flag{大如g666,则就无法确定flag所在字段了,但返回1^0,则可以说明flag绝对不在第一个字段,一般来说,数据库表的第一个字段都是id,所以我们可以直接猜第一个字段的值为0,1,2,3,4,5……..,一般id都从1开始
构造最终payload:
1 | |
脚本:
1 | |
输出:
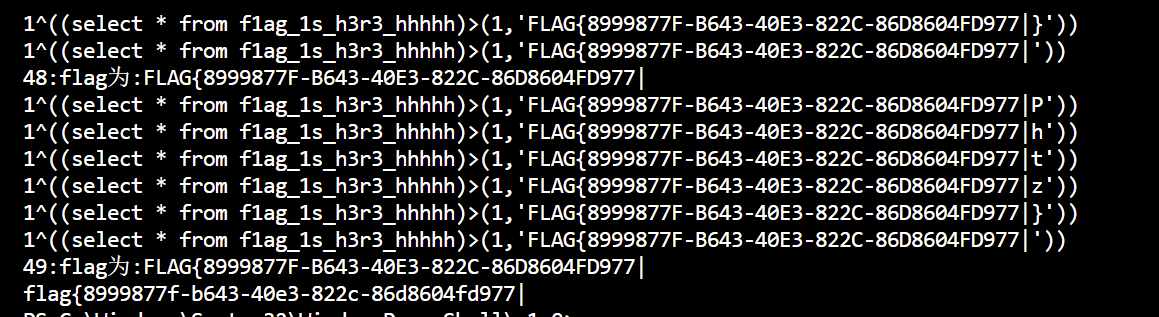
flag=flag{8999877f-b643-40e3-822c-86d8604fd977}